Every time there is a need to create a hierarchical structure from database point of view, a default design that pops up in a developer's mind is a self referencing table. However, this design may have performance issues due to recursion (recursive Common table expression [CTE]) that would need to be implemented. Recursion leads to additional logical reads. Apart from that, one other issue is, while inserting the data in self referencing table, each data node needs to be entered in certain logical order, in presence of foreign key constraint.
Out of many other approaches, one other technique that can be used for implementing hierarchy is Path Enumeration technique.
As the name suggests, in this technique, each node in the tree has an attribute that stores complete path from root up-to that specific node. This is similar to Linux file paths. This technique is much flexible when implementing, natural hierarchies, ragged hierarchies, network pattern etc. In Data warehouse / data marts such tables are called Bridge tables that separately store the Parent-child relationship with the hierarchy path code and connect directly with Fact tables.

C. Get "/" separated hierarchy description for application code
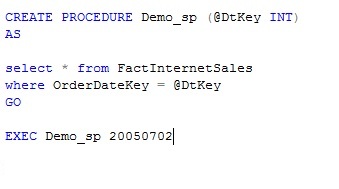
The hierarchy can also be stored with "/" separated descriptions that can be processed by application middle tier to represent in any manner as suitable for UI application. Below is an example of how this can be done.
Alternatively, the HierarchyMapDesc column can be persisted as a part of the table itself for better performance.
In below example the encoded hierarchy /1 / 4 / 5/ is converted into readable description /Equity / Depository Receipts / ADR in a separate column.
This description can be processed by middle tier for an appropriate display in UI based applications.

d. Other scenarios
Benefits
Pain points
Out of many other approaches, one other technique that can be used for implementing hierarchy is Path Enumeration technique.
As the name suggests, in this technique, each node in the tree has an attribute that stores complete path from root up-to that specific node. This is similar to Linux file paths. This technique is much flexible when implementing, natural hierarchies, ragged hierarchies, network pattern etc. In Data warehouse / data marts such tables are called Bridge tables that separately store the Parent-child relationship with the hierarchy path code and connect directly with Fact tables.
Hierarchy Use Case
We need to design a hierarchy for below classification of financial instruments. How do we design this? |
| Figure 1 |
Table Design
Below is the table structure that can be implemented. |
| Figure 2 |
- Instrument Type stores a unique list of nodes. Sample data in Figure 3 below.
- Instrument Type Hierarchy would store the relationships between nodes. Sample data Figure 4 below.
- Here we have HierarchyMapCd which stores the path to the hierarchy.
- NodeTypeInd would be R (Root), I (Intermediate) or L(Leaf)
- HierarchyLevelNbr would represent the level at which the node is in the hierarchy with Top node being at Level 0.
Instrument Type Sample Data
 |
| Figure 3 |
Instrument Type Hierarchy Sample Data
 |
| Figure 4 |
Understanding Hierarchy Path Code Creation
Let's take a sample piece of hierarchy that needs to be stored in our table design.
- BOND
- GOVERNMENT
- BILL
- NOTES
- GOVERNMENT BONDS
Each of the items individually are distinct nodes that would be stored in InstrumentType table and they get their own unique identifiers.
InstrumentTypeId
|
InstrumentTypeNm
|
7
|
Bond
|
8
|
Government
|
9
|
Bill
|
10
|
Notes
|
11
|
Government Bonds
|
Now in order to construct HierarchyPathCd for Bill, we would construct a "/" separated string of all InstrumentTypeId from Parents to child. So in this case it would be
/7/8/9/. This represents /Bond/Government/Bill.
Similarly,
- Notes would be /7/8/10/
- Government Bonds would be /7/8/11/
Implementation for few scenarios below
a. Get entire hierarchy under "Bond" (top down)
b. Get all nodes above "Variable Rate" Bonds (bottom up)

C. Get "/" separated hierarchy description for application code
The hierarchy can also be stored with "/" separated descriptions that can be processed by application middle tier to represent in any manner as suitable for UI application. Below is an example of how this can be done.
Alternatively, the HierarchyMapDesc column can be persisted as a part of the table itself for better performance.
In below example the encoded hierarchy /1 / 4 / 5/ is converted into readable description /Equity / Depository Receipts / ADR in a separate column.
This description can be processed by middle tier for an appropriate display in UI based applications.
d. Other scenarios
- Get only the root nodes. hint - filter on NodeTypeInd R
- Get only the leaf nodes. hint - filter on NodeTypeInd L
- Get all nodes under a subtree at certain level. hint - after filtering on subtree level, apply the filter on HierarchyLevelNbr.
- In case of a network pattern, find various paths where a node participates in a network.
Benefits
- Unlike self referencing table design, when inserting hierarchy nodes in InstrumentTypeHierarchy table, there is no need to follow a specific order as all the references are already there in InstrumentType table.
- Non recursive queries may help in countering performance issues.
- This table design, can take care of natural hierarchy, ragged hierarchy and network type of relationship between nodes. One needs to ensure that right constraints are applied for data integrity.
- Populating Hierarchy Path Codes need to be automated via scripts or a UI needs to be developed to maintain the hierarchy.
- The Hierarchy Map Codes may not correspond to actual hierarchy due to lack of constraint. Here the application team would have to ensure that right codes are being maintained.
Conclusion
Path enumerated hierarchies could be seen as another viable technique for storing hierarchical data with optimized performance while retrieving, inserting or deleting hierarchies. It can be used to store hierarchies of various types - Natural (single parent for one child), Unnatural (more than one parent for a single child, Ragged (Missing parents at certain levels) etc.
Source Code
/***************************************************************************/ /* TABLE CREATION */ /***************************************************************************/ USE testing; GO IF OBJECT_ID( 'InstrumentTypeHierarchy' ) IS NOT NULL BEGIN DROP TABLE InstrumentTypeHierarchy; END; GO IF OBJECT_ID( 'InstrumentType' ) IS NOT NULL BEGIN DROP TABLE InstrumentType; END; GO CREATE TABLE InstrumentType ( InstrumentTypeId SMALLINT IDENTITY(1, 1) , InstrumentTypeNm VARCHAR(100) NOT NULL CONSTRAINT PK_InstrumentType PRIMARY KEY(InstrumentTypeId)); GO -- business key unique index CREATE UNIQUE INDEX IX_NC_InstrumentType_InstrumentTypeNm ON InstrumentType (InstrumentTypeNm); CREATE TABLE InstrumentTypeHierarchy ( ChildInstrumentTypeId SMALLINT NOT NULL , ParentInstrumentTypeId SMALLINT NOT NULL , HierarchyPathCd VARCHAR(5000) , NodeTypeInd CHAR(1) NOT NULL , HierarchyLevelNbr TINYINT NOT NULL CONSTRAINT PK_InstrumentTypeHierarchy PRIMARY KEY(ChildInstrumentTypeId) ); GO CREATE INDEX IX_NC_InstrumentTypeHierarchy_1 ON InstrumentTypeHierarchy (ChildInstrumentTypeId); CREATE INDEX IX_NC_InstrumentTypeHierarchy_2 ON InstrumentTypeHierarchy (ParentInstrumentTypeId); CREATE UNIQUE INDEX IX_NC_InstrumentTypeHierarchy_3 ON InstrumentTypeHierarchy (HierarchyPathCd); ALTER TABLE InstrumentTypeHierarchy ADD CONSTRAINT FK_InstrumentType_InstrumentTypeHierarchy_ChildInstrumentTypeId FOREIGN KEY( ChildInstrumentTypeId ) REFERENCES InstrumentType( InstrumentTypeId ); ALTER TABLE InstrumentTypeHierarchy ADD CONSTRAINT FK_InstrumentType_InstrumentTypeHierarchy_ParentInstrumentTypeId FOREIGN KEY( ParentInstrumentTypeId ) REFERENCES InstrumentType( InstrumentTypeId ); set identity_insert InstrumentType on INSERT INTO InstrumentType( InstrumentTypeId,InstrumentTypeNm ) values(-1,'Not Applicable') set identity_insert InstrumentType off /***************************************************************************/ /* DATA CREATION */ /***************************************************************************/ INSERT INTO InstrumentType( InstrumentTypeNm ) VALUES( 'Equity' ), ( 'Common Stock' ), ( 'Preferred Stock' ), ( 'Depository Receipts' ), ( 'ADR' ), ( 'GDR' ), ( 'Bond' ), ( 'Government' ), ( 'Bill' ), ( 'Note' ), ( 'Government Bond' ), ( 'Municipal' ), ( 'Agency' ), ( 'Corporate' ), ( 'Fixed Rate' ), ( 'Variable Rate' ), ( 'Asset Backed Security' ), ( 'Mortgage Backed Security' ), ( 'Collateralized Debit Obligation' ), ( 'Money Market Security' ), ( 'Derivative' ), ( 'Futures' ), ( 'Forwards' ), ( 'Options' ), ( 'Swaps' ); INSERT INTO InstrumentTypeHierarchy ( ChildInstrumentTypeId, ParentInstrumentTypeId, HierarchyPathCd, NodeTypeInd, HierarchyLevelNbr ) VALUES( 1, 1, '/1/', 'R', 0 ), ( 2, 1, '/1/2/', 'L', 1 ), ( 3, 1, '/1/3/', 'L', 1 ), ( 4, 1, '/1/4/', 'I', 1 ), ( 5, 4, '/1/4/5/', 'L', 2 ) , ( 6, 4, '/1/4/6/', 'L', 2 ), ( 7, 7, '/7/', 'R', 0 ), ( 8, 7, '/7/8/', 'I', 1 ), ( 9, 8, '/7/8/9/', 'L', 2 ), ( 10, 8, '/7/8/10/', 'L', 2 ) , ( 11, 8, '/7/8/11/', 'L', 2 ), ( 12, 7, '/7/12', 'L', 1 ), ( 13, 7, '/7/13/', 'L', 1 ), ( 14, 7, '/7/14/', 'I', 1 ), ( 15, 14, '/7/14/15/', 'L', 2 ), ( 16, 14, '/7/14/16/', 'L', 2 ), ( 17, 7, '/7/17/', 'L', 1 ), ( 18, 7, '/7/18/', 'L', 1 ), ( 19, 7, '/7/19/', 'L', 1 ), ( 20, 7, '/7/20/', 'L', 1 ), ( 21, 21, '/21/', 'R', 0 ), ( 22, 21, '/21/22/', 'L', 1 ), ( 23, 21, '/21/23/', 'L', 1 ), ( 24, 21, '/21/24/', 'L', 1 ), ( 25, 21, '/21/25/', 'L', 1 ); /***************************************************************************/ /* UTILITY FUNCTIONS */ /***************************************************************************/ IF OBJECT_ID(N'ConvertStringToTable', N'TF') IS NOT NULL DROP FUNCTION ConvertStringToTable GO CREATE FUNCTION dbo.ConvertStringToTable ( @InputString VARCHAR(MAX) , @Separator CHAR(1) ) RETURNS @Result TABLE(ID INT identity(1,1), Value VARCHAR(MAX)) AS BEGIN DECLARE @XML XML; SET @XML = CAST(('<row>'+REPLACE(@InputString, @Separator, '</row><row>')+'</row>') AS XML); INSERT INTO @Result SELECT t.row.value('.', 'VARCHAR(MAX)') FROM @XML.nodes('row') AS t(row) WHERE t.row.value('.', 'VARCHAR(MAX)') <> ''; RETURN; END; GO IF OBJECT_ID(N'GetHierarchyMapDescription', N'FN') IS NOT NULL DROP FUNCTION GetHierarchyMapDescription GO CREATE FUNCTION dbo.GetHierarchyMapDescription ( @InputString VARCHAR(MAX) ) RETURNS VARCHAR(MAX) AS BEGIN DECLARE @Result VARCHAR(MAX) select @Result = COALESCE(@Result + '/', '') + InstrumentTypeNm from dbo.ConvertStringToTable(@InputString,'/') F inner join InstrumentType IT ON IT.InstrumentTypeId = F.Value RETURN @Result END; go /***************************************************************************/ /* SAMPLE QUERIES */ /***************************************************************************/ -- Get entire hierarchy bond and all its types (top down) DECLARE @InstrumentType VARCHAR (500) = 'Bond' -- search string here DECLARE @HierarchyMapCd VARCHAR(5000) SELECT @HierarchyMapCd = ITH.HierarchyPathCd FROM InstrumentTypeHierarchy AS ITH INNER JOIN InstrumentType AS ITC ON ITH.ChildInstrumentTypeId = ITC.InstrumentTypeId WHERE ITC.InstrumentTypeNm = @InstrumentType SELECT ITC.InstrumentTypeNm, ITH.HierarchyLevelNbr, ITH.HierarchyPathCd FROM InstrumentTypeHierarchy ITH INNER JOIN InstrumentType ITC ON ITH.ChildInstrumentTypeId = ITC.InstrumentTypeId INNER JOIN InstrumentType ITP ON ITH.ParentInstrumentTypeId = ITP.InstrumentTypeId WHERE ITH.HierarchyPathCd LIKE @HierarchyMapCd + '%' order by HierarchyPathCd, HierarchyLevelNbr GO -- Find hierarchy nodes above "Variable Rate" bond type (Bottom up) DECLARE @InstrumentType VARCHAR (500) = 'Variable Rate' -- search string here DECLARE @HierarchyMapCd VARCHAR(5000) SELECT @HierarchyMapCd = ITH.HierarchyPathCd FROM InstrumentTypeHierarchy AS ITH INNER JOIN InstrumentType AS ITC ON ITH.ChildInstrumentTypeId = ITC.InstrumentTypeId INNER JOIN InstrumentType AS ITP ON ITH.ParentInstrumentTypeId = ITP.InstrumentTypeId WHERE ITC.InstrumentTypeNm = @InstrumentType IF OBJECT_ID('tempdb..#TmpTableFormatCode ') IS NOT NULL DROP TABLE #TmpTableFormatCode select * INTO #TmpTableFormatCode from dbo.ConvertStringToTable(@HierarchyMapCd,'/') SELECT IT.InstrumentTypeNm, ITH.HierarchyLevelNbr, ITH.HierarchyPathCd FROM InstrumentTypeHierarchy ITH INNER JOIN #TmpTableFormatCode P ON P.Value = ITH.ChildInstrumentTypeId INNER JOIN InstrumentType IT ON IT.InstrumentTypeId = ITH.ChildInstrumentTypeId ORDER BY ID ASC -- Get "/" separated hierarchy description for application select ITH.*, dbo.GetHierarchyMapDescription(HierarchyPathCd) AS HierarchyMapDesc from InstrumentTypeHierarchy ITH