Before jumping to the topic of partitioning design patterns, I would brush up on the basic concepts of partitioning.
What is Partitioning?

Why Partition?
So what are the situations when one would need to consider partitioning?
Limitations of Partitioned Tables
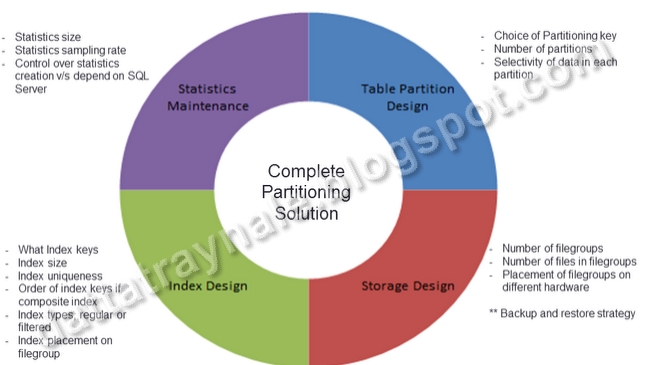
Partitioning implementation might look like an easy implementation, but its really a complex process. Just knowing partitioning feature is not enough to come up with a really performing partitioning solution. The scope of a partitioning solution is much bigger that I have tried to put in the diagram below. The design decisions that need to be taken in each area are listed in the bulletted points next to each quadrant. Wrong decisions in these areas will lead to poorly implemented partitioning solution. Which means, the person who is responsible for this implementation should also know other internal aspects of SQL Server. This diagram can be seen as a check-list for such implementation.
Partitioning Design Pattern:1 (Basic)

-------------------------------------------------------------
Concepts
Benefits of multiple filegroup based design
Design Pattern:2 (Non aligned Partition Indexes)
Design Pattern:3 (Partition aligned regular indexes)
 Pros
Pros
-------------------------------------------------------------
Concepts
Partitioned View

Advantages of partitioned views based design
Design Pattern:4 (Partitioned View + Partitioned Table)

How this works?
Cons
This solution is recommended. I will be writing in-detail on this solution in a separate post.
Design Pattern:5 (Partitioned filtered indexes)
 Pros
Pros
What is Partitioning?
- In general, partitioning means breaking “something” into manageable pieces.
- From database point of view:
- Functionality to horizontally split the table while maintaining a single logical object.
- This can a feature coming with a DB product, or it can be designed to achieve the same functionality.
- There are two types of database partitioning that can be implemented by partitioning a table vertically or horizontally.
Partitioned Table

So what are the situations when one would need to consider partitioning?
- One or more tables would grow around 40+ GB. And that will lead to the issues below…
- Query processing performance is a concern.
- DBA operations like index rebuild, statistics update, backups, restores, recovery are time consuming (Availability issues)
- Slow Data Load / Archive / Delete operations
Limitations of Partitioned Tables
- A specific partition can be rebuilt only offline (Restriction). This is an issue for global applications.
- Online index rebuild takes ages in monster tables. That also leads to multiple other problems.
- System performance is impacted during online rebuild
- Extra space : table with 500 GB data, Clustered Index rebuild needs 1.1 TB space (500 GB data part + 100 GB sorting space + 500 GB log generated) Apart, mirroring traffic (if mirroring implemented). If this space is not available, then indexes cannot be rebuilt.
- Resource abuse : rebuilding static part of data, when it can be done once.
- Skewed/Inaccurate statistics leading to performance issues.
Partitioning implementation might look like an easy implementation, but its really a complex process. Just knowing partitioning feature is not enough to come up with a really performing partitioning solution. The scope of a partitioning solution is much bigger that I have tried to put in the diagram below. The design decisions that need to be taken in each area are listed in the bulletted points next to each quadrant. Wrong decisions in these areas will lead to poorly implemented partitioning solution. Which means, the person who is responsible for this implementation should also know other internal aspects of SQL Server. This diagram can be seen as a check-list for such implementation.
Partitioning Design Pattern:1 (Basic)

Cons- Specific partition can only be rebuilt in offline mode.
- Online index rebuilds take long, impacting the application performance.
- Index rebuild may fail due to DB space issues.
- Statistics issues – stats invalidation takes longer in big tables, skewed statistics, stats rebuild with full scan drains out resources.
- Takes longer to backup and restore.
- Piecemeal restore not available due to single filegroup.
- High storage costs.
-------------------------------------------------------------
Concepts
Benefits of multiple filegroup based design
- Cost Effectiveness : More actively used data placed on high perf hardware (e.g. Solid state drive/Raid 10) and less frequently accessed in less expensive/low performing hardware.
- Narrow maintenance window : File/File groups help piecemeal data backups and restores. Static data need to be backed only once, leading to Storage costs reduction (SAN is expensive).
- Better Availability : Partial database recovery is possible. More important/actively used data can be brought online soon. In case of file corruption only the impacted filegroup is not available.
Design Pattern:2 (Non aligned Partition Indexes)
Pros

- Parallel access to indexes and data
- Specific partition can only be rebuilt in offline mode.
- Online index rebuilds take long, impacting the application performance.
- Index rebuild may fail due to DB space issues.
- Statistics issues – stats invalidation takes longer in big tables, skewed statistics, stats rebuild with full scan drains out resources.
- If index filegroup gets corrupted/offline, then the entire table is in accessible.
- Partial database recovery can be implemented, but less efficient and not a clean solution.
Design Pattern:3 (Partition aligned regular indexes)

- Partitioned table advantages.
- Specific partition can only be rebuilt in offline mode.
- Online index rebuilds take long, impacting the application performance.
- Index rebuild may fail due to DB space issues.
- Statistics issues – stats invalidation takes longer in big tables, skewed statistics, stats rebuild with full scan drains out resources.
- Partial database recovery possible but not a clean solution
-------------------------------------------------------------
Concepts
Partitioned View

Advantages of partitioned views based design
- Table Elimination for query performance. This can be achieved by adding a check constraint in table for every year on the partition Column (Eg date).
- Different indexes can be created on underlying tables. For instance, index based on access patterns, different fill factors etc. based on usage.
- Statistics is not/less skewed. More accurate stats lead to better execution plans, thereby better performance.
- Stats update operations need to be done only for current year. Previous years are untouched. Huge reduction in maintenance window.
- Online index rebuild is supported for an entire table for a particular data set. Other static data need not be rebuilt. This will save space requirements just to rebuild large indexes, which translates to more cost.
- Not required data can be deleted in micro-milli-secs, by dropping the table itself and updating the view.
Design Pattern:4 (Partitioned View + Partitioned Table)

How this works?
- Data for each year stored in separate physical table.
- Each physical table stored on one separate file group with 4 files each.
- Each filegroup is stored on a different storage drive based on workload.
- All the data is combined in one view.
- Queries refer to the view
- Combines the advantages of
- Partitioned Tables
- Partitioned Views
- Multiple file group based design
Cons
- Any change in table schema need to be reflected in all the underlying tables.
- Can have max of 255 tables in a view

- Partitioned table advantages
- Better statistics for Non clustered indexes.
- Online rebuild of NC filtered indexes less resource intensive
Cons
- The clustered index is still one huge index which if fragmented will lead to long build time.
- Micro management of statistics maintenance for filtered indexes. Cannot rely on SQL server.
- Filegroup based backups possible but not a clean solution
-
Please leave your comments if you liked/have suggestions for this blog post.
No comments:
Post a Comment